Scouter APM 소소한 시리즈 #4 - XLog 활용 - 상세기능
Scouter is an APM optimized for developers.
XLog 활용
Scouter 개발시 가장 중점을 두었던 것 중 하나가 "XLog 차트 안에서 모든 문제를 다 해결할 수 있도록 하자" 였습니다. 그래서 XLog 차트는 상당히 많은 기능을 가지고 있으며 그중 중요한 기능들에 대해 설명하도록 하겠습니다.1. XLog의 조작
(1) 키보드를 통한 간편 이동
- 실시간 XLog 차트에서 키보드를 사용하여 XLog 차트의 시간을 이동시킬수 있습니다. 이를 통해 가까운 과거 시점으로 빠르게 이동이 가능합니다. (큰 시간을 이동하여야 하면 Load History 메뉴를 사용하여야 합니다.)
- 좌우 화살표 : 한번 누르는 경우 10초를 이동합니다.
- 상하 화살표 : 한번 누르는 경우 일정한 비율로 Y축의 스케일을 조절합니다.
(2) Y축 항목 변경
 |
| <그림. XLog Y축 항목 변경> |
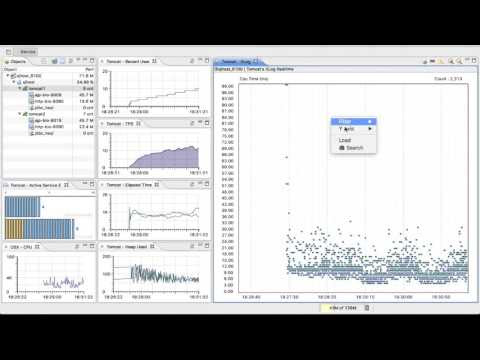
- Y축 항목을 응답시간(ElapsedTime)이 아닌 다른 값으로 변경할 수 있습니다.
- 현재 서비스가 CPU bound인지 혹은 SQL이나 Api call bound인지를 한눈에 파악할때 주로 사용하게 됩니다.
- 혹은 SQL 호출 회수가 많은 서비스를 골라내거나, 메모리 사용량이 많은 서비스를 골라낼때 사용하기도 합니다.
(3) Load History
- 과거 특정 시점의 XLog 차트를 로드하기 위해 사용합니다.
(4) Summary
 |
| <그림. XLog 통계> |
- 화면에 표현된 XLog 점들에 대한 통계를 바로 확인할 수 있는 기능입니다.
- 예를 들면 각 서비스에 대한 총 호출 건수 및 총 응답시간, 평균 응답시간, SQL 및 API 호출에 대한 평균 응답시간 등을 확인할 수 있습니다.
(5) Filter
XLog를 통한 분석시 가장 많이 사용되는 기능중의 하나입니다.
원하는 조건의 XLog 점들만 보여지도록 하는 기능으로 필터를 적용하면 XLog 차트의 배경색이 에메랄드 색으로 변경됩니다.
 |
| <그림. XLog Filter> |
- Service : Service명으로 Filter 적용
- IP : IP로 Filter 적용
- StartHMS: 요청 시작 시간으로 Filter 적용
- User-Agent: user agent 값으로 Filter 적용
- Login, desc, text1~5: agent plugin으로 적용한 사용자 정의 값에 대한 filter 적용
- 빠른 필터 : SQL이 포함된 요청, Api 호출이 포함된 요청, Error가 발생한 요청
- 각 값은 특정한 와일드 카드 형식으로 표현이 가능합니다.(당연히 정확한 값의 경우가 검색이 빠릅니다.)
- 단어의 가장 앞, 가장 끝, 그리고 중간에 각 하나씩 최대 3개의 *를 사용할 수 있습니다.
- 예를 들어 /user/100<GET>라는 요청은 /user*, *user*, 또는 *us*r* 등으로 검색이 가능합니다.
(6) Search
과거 시점의 XLog 목록을 특정 조건으로 조회하는 기능입니다.
(반면에 Load History는 과거 시점의 XLog 차트를 열어주는 기능임)
(반면에 Load History는 과거 시점의 XLog 차트를 열어주는 기능임)
 |
| <그림. XLog Serach> |
2. XLog 관련 주요 설정
XLog의 목적은 시스템에 발생하는 문제를 빠르게 인지하고 원인을 파악하여 해결하기 위함입니다.이러한 목적을 잘 달성하기 위해서는 모니터링 대상 시스템을 잘 추적할 수 있도록 설정하는 것이 도움이 됩니다.
단 추가된 설정만큼 저장되는 데이터의 양이 많아지고 과도한 정보를 profiling하는 것은 오히려 분석에 방해가 되는 경우가 있으므로 시스템 상황에 맞게 적절히 조절할 것을 권장합니다.
(1) method profiling
Scouter의 profiling은 주로 외부 연동 정보를 위주로 profiling을 하게 되므로 보다 상세한 profiling이 필요한 경우 보통 가장 먼저 설정하는 부분입니다.모니터링 대상 코드를 분석 후 아래 옵션을 통해 추가적으로 profiling 할 method를 지정해 줍니다.
아래 옵션을 지정하면 profile에 지정한 method가 추가됩니다.
hook_method_patterns=comp.order.*Controller.*,comp.order.*Service.*,comp.order.*Repository.*Patterns 설정 방법
Scouter 설정 중 이름이 patterns로 끝나는 경우는 대부분 아래와 같은 형식으로 사용할 수 있습니다.
- 예시
- com.sc.*.* : com.sc. 으로 시작하는 패키지내의 모든 class의 모든 method
- com.sc.order.Order.* : com.sc.order.Order class의 모든 method
- com.sc.order.*Service.* : com.sc.order. 패키지의 class중 Service로 끝나는 class의 모든 method
- com.sc.order.Order.findOrder : com.sc.order.Order class의 method중 findOrder method
- com.sc.order.Order.find* : 인식되지 않음, method명에는 *를 조합하여 사용할 수 없음.
method profiling은 public method에만 작동합니다.
다른 접근 제한자에 대한 profiling을 허용하려면 다음 옵션을 사용합니다.
다른 접근 제한자에 대한 profiling을 허용하려면 다음 옵션을 사용합니다.
hook_method_access_public_enabled=true
hook_method_access_private_enabled=false
hook_method_access_protected_enabled=false
#Activating default Method hooking
hook_method_access_none_enabled=false
Scouter 옵션 중 "hook_"로 시작하는 옵션은 모두 모니터링 대상 object(주로 tomcat등의 java application)를 재시작해야 적용이 됩니다.
또한 보다 상세한 제어가 필요한 경우 아래 옵션들을 복합적으로 사용하게 됩니다.
hook_method_exclude_patterns=
hook_method_ignore_classes=
hook_method_ignore_prefixes=get,set #기본값
(2) http header 와 form parameter profiling
필요한 경우 http header 및 form parameter 정보를 profiling 할 수 있습니다.#http header 정보를 profile 합니다. profile_http_header_key가 정의되지 않았으면 전체 header를 profile합니다.
profile_http_header_enabled=false
#profile할 http header의 이름들을 comma로 구분하여 기입합니다.
profile_http_header_keys=
Form parameter 또는 query string을 profiling 하기 위해서는 아래 옵션을 사용합니다.
profile_http_parameter_enabled=false
profile_http_querystring_enabled=false
추가로 Spring controller method의 parameter를 profiling 하기 위해서는 아래 옵션을 사용합니다.
#Spring의 request mapping method의 parameter를 profiling합니다.
#profiling되는 값은 각 파라미터 오브젝트의 toString() method의 값입니다.
profile_spring_controller_method_parameter_enabled=false
그리고 XLog 정보에는 ip 정보가 포함되는데 proxy 등을 경유하는 경우 사용자 IP를 (x-forwarded-for 같은) http header에서 구해오도록 설정할 수 있습니다.
디스크 용량이 한도를 넘어서게 되면 무조건 과거 데이터부터 삭제를 하게 되므로 한도 용량을 넘어서지 않도록 적절히 조절하여 설정하는 것이 중요합니다.
일반적으로 profile의 저장 기간을 가장 짧게 설정하고 성능 카운터의 정보를 가장 길게 유지합니다.
- 아래 설정들은 java agent 설정이 아닌 collector server의 설정입니다.
trace_http_client_ip_header_key=
(3) XLog 를 error로 마킹하기
XLog는 아래의 상황에서만 error로 마킹됩니다.- Sevlet 및 Filter에서 까지 exception handling이 되지 않은 경우
- 외부로 요청한 통신에서 에러가 발생한 경우
- SQL Exception이 발생한 경우
- SQL 수행 시간이 매우 느린 경우(30초)
- SQL의 fetch 건수가 많은 경우(10000건)
추가적인 경우에 error 마킹을 하려면 아래 옵션들을 사용합니다.
#error로 마킹할 Exception class pattern을 지정합니다.
#상속받은 Exception class의 이름까지 검색합니다.
hook_exception_class_patterns=my.app.SereiousException,my.app.svc.*Exception
#위 패턴에서 제외할 패턴을 지정합니다.(예를 들어 MyPjtException을 지정하였으나, 이를 상속받은 MyPjtBizException은 제외하려면 여기에 설정합니다.)
hook_exception_exclude_class_patterns=
#Exception handler method의 pattern을 지정합니다. 이 메소드로 전달되는 Exception class의 정보로 error 정보를 profiling 합니다.
hook_exception_handler_method_patterns=my.app.myHandler.handleException
#위 메소드에 전달되는 Exception 중 error 마킹에서 제외할 class 정보를 입력합니다.
hook_exception_handler_exclude_class_patterns=
또한 error 발생시 profile에 full stack trace를 남기거나 기본 제공되는 error 옵션을 변경하려면 아래 설정들을 사용하면 됩니다.
profile_fullstack_hooked_exception_enabled=false
xlog_error_on_sqlexception_enabled=true
xlog_error_on_apicall_exception_enabled=true
xlog_error_on_redis_exception_enabled=true
xlog_error_sql_time_max_ms=30000
xlog_error_jdbc_fetch_max=10000
(4) XLog 샘플링하기 (일부의 XLog만 저장하기)
저는 샘플링을 안하는 것을 선호합니다만 경우에 따라서는 (디스크가 아주 작은 장비를 사용 한다던지 혹은 하나의 수집서버로 수십개 이상의 시스템을 모니터링 해야 한다던지...) 샘플링 해야 하는 경우가 있습니다. 이 경우에 아래 옵션들을 적절히 조합하면 필요한 정보들을 최대한 유지하면서 효율적으로 샘플링을 할 수 있습니다.##### [XLog Sampling] #####
xlog_sampling_enabled=false
#xlog는 유지하고 profile 정보만 샘플링한다.
xlog_patterned_sampling_only_profile=false
xlog_sampling_step1_ms=100
xlog_sampling_step1_rate_pct=3
xlog_sampling_step2_ms=200
xlog_sampling_step2_rate_pct=10
xlog_sampling_step3_ms=500
xlog_sampling_step3_rate_pct=30
xlog_sampling_over_rate_pct=100
##### [XLog Patterned Sampling] #####
xlog_patterned_sampling_enabled=false
xlog_patterned_sampling_service_patterns=
#xlog는 유지하고 profile 정보만 샘플링한다.
xlog_patterned_sampling_only_profile=false
xlog_patterned_sampling_step1_ms=100
xlog_patterned_sampling_step1_rate_pct=3
xlog_patterned_sampling_step2_ms=1000
xlog_patterned_sampling_step2_rate_pct=10
xlog_patterned_sampling_step3_ms=3000
xlog_patterned_sampling_step3_rate_pct=30
xlog_patterned_sampling_over_rate_pct=100- 전체 XLog를 대상으로 샘플링
- xlog_sampling 으로 시작하는 옵션을 사용합니다.
- 응답시간에 따라 4단계로 샘플링하는 비율을 지정할 수 있습니다.
- 특정 패턴의 url에 샘플링
- 전체 샘플링 보다 우선하여 적용됩니다.
- xlog_patterned_sampling 으로 시작하는 옵션을 사용합니다.
XLog 샘플링 옵션을 적용하여도 TPS나 서비스 호출건수등의 카운터 정보에는 영향을 주지 않습니다.그리고 xlog discard 옵션을 사용하면 TPS등에 반영되지도 않습니다. 보통 health check 요청등을 무시하기 위해 사용됩니다.
xlog_discard_service_patterns=
#error 발생시에는 xlog에 기록한다.
xlog_discard_service_show_error=true
3. Scouter 서버의 데이터 저장 공간 설정
xlog와 profile은 서버 저장 공간 중 가장 많은 부분을 차지하는 데이터입니다.디스크 용량이 한도를 넘어서게 되면 무조건 과거 데이터부터 삭제를 하게 되므로 한도 용량을 넘어서지 않도록 적절히 조절하여 설정하는 것이 중요합니다.
일반적으로 profile의 저장 기간을 가장 짧게 설정하고 성능 카운터의 정보를 가장 길게 유지합니다.
- 아래 설정들은 java agent 설정이 아닌 collector server의 설정입니다.
#데이터 저장소의 위치는 scouter server가 설치된 경로 하위의 database 디렉토리입니다.
db_dir=./database
#디스크의 특정 용량을 초과하면 과거 데이터부터 삭제합니다.
mgr_purge_disk_usage_pct=90
#프로파일 데이터를 유지하는 기간(일반적으로 가장 큰 사이즈의 데이터입니다.)
mgr_purge_profile_keep_days=10
#XLog를 유지하는 기간
mgr_purge_xlog_keep_days=30
#성능 카운터 정보를 유지하는 기간
mgr_purge_counter_keep_days=70
db 디렉토리에 들어가면 각 날짜별 항목별 데이터의의 사이즈가 얼마나 되는지 확인할 수 있습니다.
덕분에 도움이 되었습니다.
답글삭제한군데 수정이 필요한 부분이 있는 것 같아 글 남겨 봅니다.
##### [XLog Sampling] #####
xlog_sampling_enabled=false
#xlog는 유지하고 profile 정보만 샘플링한다.
xlog_patterned_sampling_only_profile=false <=== xlog_sampling_only_profile
xlog_sampling_step1_ms=100
xlog_sampling_step1_rate_pct=3
profile_fullstack_hooked_exception_enabled=false
답글삭제xlog_error_on_sqlexception_enabled=true
xlog_error_on_apicall_exception_enabled=true
xlog_error_on_redis_exception_enabled=true
xlog_error_sql_time_max_ms=30000
xlog_error_jdbc_fetch_max=10000
위 옵션들은 어디에 작성하는것인가요?
scouter server 에 작성하나요 아니면
agent 쪽 에 설정파일에 작성하나요?
xlog profile hook 등은 모두 agent 설정입니다
삭제안녕하세요. Scouter 를 사용하다 막히는 부분이 있어 질문 드립니다.
답글삭제OS의 경우 Memory를 체크해서 알림으로 보내는데
JAVA 에서 Heap Memory를 체크해서 알림으로 보낼수는 없을까요?
Agent.java의 소스에서 수정이 필요할까요??
0chitiYmune_1982 Bianca Gutierrez https://wakelet.com/wake/1ob-P2JYLhAAXc_mk45NC
답글삭제anabolri
0idinMcons_ya Donald Robinson click
답글삭제get
uneninel