나는 왜 Reactive streams와 친해지지 않는가?
Reactive stream에 관심을 갖게 된 건 2017년 스프링캠프를 통해서이다.

그 때 나는 비동기 어플리케이션의 추적(Tracing)에 빠져 있어, 스프링캠프에서 관련된 세션을 발표했는데 이 세션에서 언급된 비동기 어플리케이션이 reactive streams를 지칭한 것은 아니었다. (스프링캠프 : 비동기 어플리케이션 모니터링과 밀당하기)
Reactive stremas와 webflux는 이름 정도만 아는 수준이었는데 스프링캠프의 토비님 세션을 통해 좀 더 알게 되었다. (스프링캠프: Spring Webflux)
지금도 잘 이해하고 있는 것은 아니지만 그 당시에는 그저 비동기 논블로킹을 구현하는 또 다른 스타일 또는 nodejs와 유사한 이벤트 루프 처리와 콜백 헬을 좀 더 우아하게 처리하는 방법인가? 정도로만 생각했고 webflux 공식 버전이 나온것도 아니기에 관심이 오래가지는 않았다.
그러다 관련된 정보들이 점점 많아지고 주변에서도 이를 사용하기 시작하면서 나도 개발중인 시스템에 적용하게 되었다. 특히 사용하는 시스템들이 늘어나다 보니 SCOUTER에서도 webflux에 대한 추적을 지원할 필요가 있었다.
그런데 webflux로 개발을 하거나 관련 코드를 볼때 뭔가 불편한 이질감을 떨칠 수가 없었고 종종 "내가 지금 왜 이러고 있나~"라는 멍타임이 오곤 했는데, 주변 개발자들도 "나도 그렇다!" 라는 얘기들을 하여 이참에 이 이질감의 정체를 밝혀 보려고 한다.
그럼 먼저 개발 관점에서 reactive streams의 몇가지 장점을 한번 짚어보자.
- 일괄 처리
- 백프레셔
- 스트림을 다룰때의 풍성한 표현력
또한 reactive streams는 당연히 비동기 논블로킹 프로그래밍의 장점을 가지고 있다.
- C10K 문제 해결
비동기 논블로킹 프로그래밍의 장점으로 많이 얘기되는 것이 C10K 문제의 해결, 즉 "만개의 클라이언트를 동시에 처리할 수 있는가?" 이다.
소켓은 동시에 수백만개를 열 수 있는 반면, 블로킹 프로그램에서는 많아야 수천개만 동시에 처리할 수 있는데, 이 불일치를 해결하기 위한 방법으로 비동기 논블로킹 프로그래밍이 인기를 끌고 있는 것이다.
이처럼 C10K 문제의 우아한 해결과 풍성한 표현력, 백프레셔 등 기술에 대한 우수함은 이해가 가지만 왠지 정이 가지 않고 친해지지 않는 reactive streams, 이제부터 개인 감성으로 이넘에 대한 불만을 한번 터뜨려 보겠다.
먼저 난 운영 관점에서 추적성을 아주 중요하게 생각하는데 스택 트레이스에 컨텍스트가 유실되는게 가장 먼저 짜증으로 다가왔다. 최신 버전의 reactor에서는 여기 인위적인 정보를 삽입하여 보완해주기는 하지만 여전히 난해하고 코드와 일치하지 않는다.
특히나 IO 수행중에는 할당된 스레드가 없기 때문에 스레드 덤프를 통해 알 수 있는 정보는 더욱 제한적이다.
(비동기 논블로킹 프로그램과 동일한 문제를 가지고 있지만 reactor에서는 바인딩된 스레드의 스택트레이스 조차 거의 쓸모가 없는 경우가 많아 더욱 짜증을 불러 일으킨다.)
 |
 |
| 그림. 블로킹 프로그램에서의 스택트레이스 |
 |
 |
| 그림. 비동기 프로그램에서의 스택트레이스 |
두번째로, 내가 작성하는 비즈니스 로직이 Mono와 Flux에 매몰되어 로직이 주인인지 reactor가 주인인지 조차 헷갈릴 정도로 래퍼들로 도배되고 특히나 여러개의 Mono, Flux를 합쳐야 하는 경우는 원본 객체가 Mono를 입었다 벗었다 하면서 혼란을 가중시켰으며 내가 짠 코드를 읽을 때 조차 순간적으로 비즈니스 로직이 잘 보이지 않는 마법같은 일이 발생하곤 했다.
이로 인해 순간적으로 뇌가 멈추는 현타에 종종 빠지며 reactor가 제공하는 풍성한 연산자들 조차도 그냥 이 불편함을 보완해 주는 장치로 느껴졌다. 수많은 연산자들... 구지 이걸 내가 다 알아야 하는 것인가?
얼마 전에는 카카오테크에 한 아티클이 올라왔는데 (사용하면서 알게 된 Reactor, 예제 코드로 살펴보기) 글의 내용에 집중되기 보다는, 과연 비즈니스 어플리케이션을 개발할때 이런 고민까지 하는 것이 정상인가? 라는 생각이 먼저 들었다.
| 그림. Reactor의 switchMap() 연산자 |
뭐 그랬다. 지금까지 다른 새로운 것들을 접할때와 달리 그냥 노오력~이 부족해서 친해지지 않는다고 치부하기에는 좀 이상했다. (물론 노오력~을 더 하면 더 친해지긴 하겠지...)
그렇다면 다시 한번 냉정히 생각해보자.
정말 왜 그럴까? 왜 이런 불편함이 느껴질까?
이런 경우 보통 셋 중에 하나다.
1. reactive streams가 진짜 구리다.
2. 노오력이 부족하다.
3. 적절한 곳에 적절하게 사용되지 않았다.
"노오력 선택지"는 일단 제끼자. 사실 이 경우도 종종 있긴한데 노오력이 부족한 상태에선 절대 깨달을 수 없으니...
"진짜 구리다 선택지"는 경험상 아주 드물게 선택될 수 있으니 세번째라고 가정하고 좀 생각해 보자.
내가 webflux를 사용한 가장 중요한 이유가 무엇인가? 어떤 경우에 webmvc가 아닌 webflux를 선택하는가?
주변에 왜 사용해요? 라고 종종 물어보면 빠르고 성능이 좋아서... 라는 대답을 종종 듣는데 지금 내가 개발하는 어플리케이션은 피크 타임에도 워커 스레드가 수십개 수준이라 이런 상황에서 처리량, 응답시간 두 관점 모두 webflux가 더 나은 결과를 낼 것 같지는 않다.
내가 webflux를 선택하는 첫번째 목적은 그냥 무거운 스레드 문제(=C10K 문제)를 해결하기 위함이다.
무거운 스레드 문제
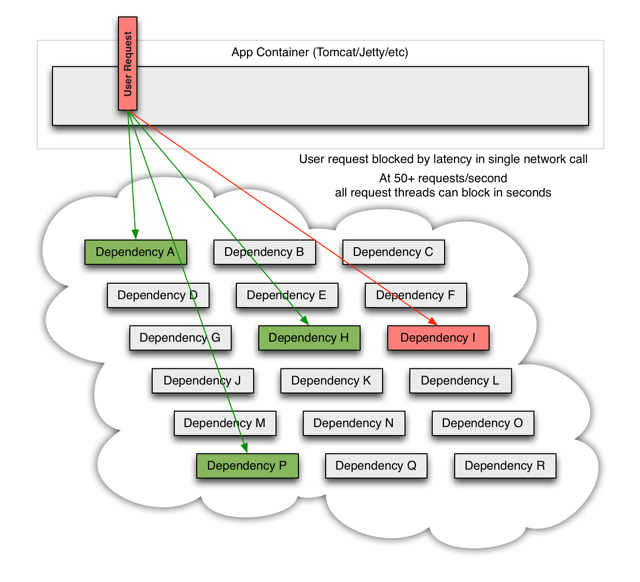
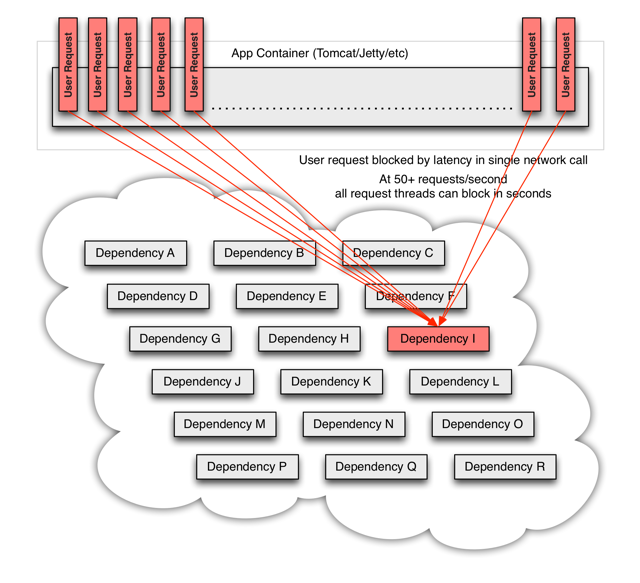
OS 스레드는 생성 유지에 사용되는 메모리량이 크고 이용되는 스레드가 많아질수록 컨텍스트 스위칭이 빈번하게 발생하며 이때 수반되는 비용도 적지 않으므로 보통 무한정 스레드를 생성하지 않고 스레드풀을 만들어 재사용 하는 식으로 개발한다. (블로킹 시스템의 경우)이런 방식에서 특정 IO(예를 들면 연동하는 다른 서비스에 대한 호출) 응답이 느려진다면 해당 스레드는 거기서 응답이 올 때까지 대기(블로킹) 하게 된다. 이 상황이 지속되면 스레드 풀에 있는 모든 스레드들이 대부분 그 위치에 오랜 시간 대기하게 되고 결국 모두 소진되어 이후 발생하는 요청이 더이상 스레드를 확보할 수 없어 실패하게 된다. 단 한 군데의 IO 지연이 발생했지만 결국 전체 시스템을 사용할 수 없는 경우가 되는 것이다.
너무나도 유명한 넷플릭스의 연쇄 실패 이미지를 보면 아마 바로 이해가 될 것이다.
이 문제를 풀기위한 대표적인 방법이 비동기 논블로킹 프로그램이다.
IO가 필요한 구간을 만나면 스레드를 반납하고 진행하던 작업은 잠시 큐에 넣어둔다. 그리고 그 IO가 끝나면 워커 스레드가 하던 일을 다시 꺼내어 다음에 만나는 IO 작업까지 수행하게 된다.오래 걸리는 IO 구간을 비동기 논블로킹으로 처리하기 때문에 적은 수의 스레드로 훨씬 많은 요청을 동시에 받아들일 수 있으며 스레드 풀이 모자라서 더이상 요청을 받아들이지 못하는 경우는 없어지는 것이다.
사실 이런 비동기 처리를 위한 프로그래밍 스타일 때문에 발생하는 많은 문제에 대해 풀어볼 썰이 있긴한데 그건 다음 번 Project Loom에 대한 글에서 같이 다뤄볼 수도 있을 것 같다.
다시 본론으로 돌아와서, 결국 난 이 문제(무거운 스레드 문제)만 해결하면 된다.
지금 개발하는 시스템은 일반적인 비즈니스 로직을 처리하는 웹 어플리케이션이고 여기에 필요한 것은 스트림이나 일괄처리나 백프레셔는 아니다. 사실 사용자에게 백프레셔를 줄 수 있는건 아니지 않는가?
이걸 해결하기 위해 webflux를 쓴다면 해결되는 문제에 비해 여기서 발생하는 단점이 너무 크다
- 쓸모 없는 스택 트레이스
- 읽기 어려운 비즈니스 로직
- 이를 더 혼란스럽게 만드는 수많은 래퍼들 Mono, Flux
그리고 이 문제는 당연히 다른 방식으로도 완화하거나 해결할 수 있다.
그래 맞아. 이거였다. 삽만 있어도 충분한데 포크레인을 쓴 거구나. ㅠ.ㅠ
이미 몇 가지 삽은 사용하고 있고 지금으로써는 이걸로도 충분한 것으로 보인다.
연쇄 실패를 방지하기 위해 타임아웃과 써킷 브레이커를 적용하고 있고 간혹 있는 대량 데이터의 조회 처리에서는 콜백 함수를 로우 핸들러에 넘겨서 response write를 하는 식으로 스트림 방식의 처리를 하고 있다.
또한 webflux를 사용한다고해서 써킷 브레이커 같은 장치가 전혀 필요 없는 것은 아니다. 스레드를 사용하지 않더라도 해당의 컨텍스트를 보유할 메모리는 필요하며 이 또한 무한정은 아니다. 그리고 처리가 늦어지는 요청을 계속 쌓아두기 보다는 차라리 빨리 실패하는 경우가 더 좋은 경우도 많다.
당분간 웹 어플리케이션 개발할때 webflux는 사용하지는 않을 것 같다. 물론 스트림을 다루고 효율적인 네트워크 처리가 중요한 어플리케이션을 개발해야 한다면 다른 여러가지와 방안과 함께 하나의 선택지가 될 수는 있겠다.
이처럼 짜증나는 무거운 스레드 문제를 좀 더 자연스럽게 풀기 위한 여정 또한 계속 할 것이고 그 중 하나로 자바의 Project Loom이 하루 빨리 완성되기를 기대하고 있으며 아마 다음 글은 Loom에 대한 글이 되지 않을까 한다.



좋은 내용 잘 읽었습니다.
답글삭제뭔지도 모르면서 써야 할때도 있죠.
답글삭제일단 쓰는 라이브러리가 reactor 기반이라던가...
정말 아무것도 모르는 사람 입장에서 WebFlux를 왜 써야하는지 언제써야하는지에 대한 관점에서 보기에는 도움 많이 되었습니다. ^^
삭제그냥 자바를 안쓰면 모든 문제가 해결되는것임을...
답글삭제자바를 안쓰면 어떤 문제가 어떻게 해결돼요?? 엔지니어 관점에서 되게 보기 불편한 글이네요 ㅋㅋ 자바 옹호자는 아니지만 그렇다고 억까는 하지맙시다. 엔지니어답게 대안을 제시해주세요.
삭제정말 몰라야 저렇게 말할 수 있는거죠 ㅋㅋ
삭제어느 회사 다니시는지 궁금하네요 ㅋㅋ
삭제보통 이런 시니컬한 척 하면서 아무나 일단 까고난 후에 그걸 포장삼아 자기가 잘하는 줄 아는.. 그래야 남들이 자길 덜 의심할거라 생각하는, 이상한 자기만의 세상에 사는 모자란 사람들 참 많죠.
삭제좋은 내용 잘 보았습니다. Webflux를 한 번 사용하고 나서 과연 webflux가 최선인가에 대해 고민하고 있는 와중에 상당히 공감이 가는 내용이였습니다. 감사합니다.
답글삭제reactor 를 요즘 돌아다니면서 공부하고 있는데, 공감되는 내용이 많아서 재밌게 읽었습니다.
답글삭제공감이 되네요. 좋은 글 잘 읽었습니다. 다른 글에서 언급하신 것 처럼 coroutine, virtual thread로 인해 webflux 진영은 점차 축소 될 것 같네요~
답글삭제재미있게 잘 읽었습니다 ㅎㅎ
답글삭제