Java의 동시성 개선을 위한 Project Loom은 reactive streams를 대체할 것인가?
Project Loom 최신 빌드
- 얼리 액세스 빌드 제공 (2020년 8월 17일)
Project Loom 의 동기
- Project Loom 제안
- Project Loom의 동기
- 자원 사용면에서 효율적이지 못한 스레드
- 작성하고 디버깅 하기 어려운 비동기 개발 방식
- 경량 스레드(파이버)를 통한 블로킹 방식의 개발로 이를 해결하기 위함
먼저 Project Loom의 제안 내용 중 프로젝트의 동기 부분만 간단히 살펴 보도록 하자
- 하나의 서버에서 수백만 개의 소켓을 다룰 수 있지만 OS 스레드를 직접적으로 사용하는 자바에서는 동시에 수천 개 이상의 요청을 효율적으로 다루기 어렵다. 이를 극복하기 위해 최근 수년 간 많은 비동기 라이브러리들이 탄생하였는데 이는 작성하고 이해하고 디버깅하기 편해서가 아니라 단지 자바의 스레드가 성능면에서 효율적이지 못하기 때문이다.
- Loom의 목표는 수백만 개를 생성할 수 있는 파이버라고 불리는 경량 스레드를 제공하여 어플리케이션 개발자들이 (이 환경에서 비용이 거의 무료인) 동기 블로킹 코드를 마음껏 사용하고 라이브러리 개발자들이 더 이상 동기 / 비동기 API를 둘 다 제공할 필요가 없게 하는 데 있다.
결국 효율이 낮은 동기 코드로 인해 서버 자원에 비용이 더 들거나 혹은 개발 및 유지보수가 어려운 비동기 코드 때문에 사람에 비용이 더 들게 되는데, 이 프로젝트에서는 성능과 사용성이 더 이상 트레이드 오프 관계가 아니게 함으로써 이를 해결한다.
그런데 위에서 언급했듯이 작성하고 디버깅하기 어렵다는 비동기 프로그래밍을 굳이 하는 이유는 무엇일까? 그리고 작성, 디버깅이 어렵다는 건 구체적으로 무얼 말하는걸까?
여기에 대해서 좀 더 자세히 들여다 보도록 하자.
비동기 프로그래밍을 하는 이유
- 성능!
- 동시성을 우아하게 처리하기 좋은 모델
비동기 프로그래밍을 하는 이유에는 다양한 이유가 있겠지만 첫번째는 단연 더 나은 성능이다.
요청 당 하나의 OS 스레드를 사용하는 블로킹 프로그램에서는 많은 스레드를 사용함으로 인해 컨텍스트 스위칭 비용이 증가하게 되고 또한 이를 효과적으로 처리하기 위해 스레드 풀을 사용하다 보면 연쇄 실패 같은 또 다른 문제가 발생하게 된다.
반면에 논블로킹 비동기 방식의 개발에서는 적은 수의 OS 스레드를 여러 요청에서 같이 사용함으로써 이를 해결한다. (여기에 대한 좀 더 많은 정보는 앞 선 글의 내용 중 무거운 스레드 문제 부분에서 확인 할 수 있다. )
그리고 비동기 프로그래밍은 동시성을 자연스럽게 다루기에 더 좋은 모델이기도 하다.
블로킹 프로그램에서는 동시성 문제를 다룰 때 보다 낮은 수준의 동기화를 직접 다루게 됨으로써 데드락이나 스레드 누수, 고갈 등의 문제를 야기하기도 한다.
그렇다면 반대로 비동기 프로그램은 어떤 문제를 가지고 있는가?
잘 알려진 콜백 헬 같은 문제들이 먼저 떠오르지만 여기서는 Project Loom의 리더인 Ron Pressler가 언급한 내용을 위주로 살펴 보도록 하자.
비동기 프로그래밍의 단점
- Why Continuations are Coming to Java 의 내용
- 제어 흐름을 잃는다
- 컨텍스트를 잃는다
- 전염성이 있다
Why Continuations are Coming to Java의 내용 중 일부인데 동영상의 14분 20초 부터 참고하면 된다.
(아래 3가지가 잘 이해되지 않는다면 꼭 보기를 추천한다. 안타깝게도 한글 자막은 없지만 영문 스크립트는 제공 되므로 구글신님을 적절히 활용하면 이해하는데 큰 무리는 없을 것이다.)
Ron Pressler는 3가지를 얘기하는데
그 중 첫번째가 제어 흐름을 잃는다는 것이다.
비동기 프로그래밍을 하다 보면 간단한 제어 흐름(조건 분기, 반복문 등)을 복잡하게 구성해야 하는 경우가 생긴다. 가장 기본적인 비동기 프로그래밍 형식에선 얼마 지나지 않아 콜백 헬이 발생하게 되고 이를 개선한 Future, Promise 혹은 Reactive stremas에서 조차 비즈니스 로직 제어에 부가적인 코드가 많이 포함되게 된다.
실제로 비동기 코드는 배우기도 어렵고 읽기도 어려우며 이로 인해 복잡한 현실 프로젝트에서 대규모 개발자들이 비동기 스타일의 개발을 하기 위해서는 많은 비용이 발생한다.
두번째로는 컨텍스트를 잃는다. (스택 트레이스가 유용하지 않다)
이는 어떤 요청을 처리하기 위해 거쳐 온 컨텍스트가 스택 트레이스에 유지되지 않는다는 것을 의미하는데 비동기 프로그래밍에서는 스레드를 넘나들며 요청이 처리되므로 이에 대한 컨텍스트가 스택 트레이스에 쌓이지 않는다.
또한 IO 대기 중인 경우에는 할당된 스레드가 없으므로 얼마나 많은 요청이 쌓여있는 건지, 그리고 얼마나 오랫동안 처리 중인 건지도 파악 할 수가 없다.
그리고 마지막으로 전염성인데 이것이 가장 큰 문제라고 말하고 있다.
예를 들면 한 메소드가 Future를 반환하면 이를 사용하는 다른 메소드도 Future를 반환해야 하며 이러한 방식은 특정 패러다임을 강제하게 하는 문제를 발생시킨다.
이것을 "함수의 색 문제"라고 하는데 동기 함수와 비동기 함수 사이에 거대한 벽이 있어 상호 연동이 쉽지 않은 문제를 말한다. 실제로 개발 시 동기 함수를 작성하고 있는 건지 비동기 함수를 작성하고 있는 건지 계속해서 의식하게 해야 하는 불편함 들이 발생하게 된다.
(함수의 색 문제에 대해서는 Bob Nystrom의 How do you color your functions? 를 참고해 보자)
비동기 프로그래밍의 단점 극복
- async / await 또는 suspend function
- 손실된 스택 트레이스의 의도적 보완
대표적으로 javascript나 C#에서 접근하는 방식인 async / await 그리고 이와 유사한 코틀린 코루틴의 suspend function이 있다.
이들은 비동기 코드를 동기적으로 작성하게 함으로써 제어 흐름을 잃는 문제를 해결한다.
그런데 사용하다 보면 동기 함수에서 비동기 함수를 호출할 수 없다는게 문득 문득 거슬리는 경우가 있다.
또한 동기 함수에서 비동기 함수를 호출하는데 제약이 따르므로 결국 작성하는 대부분의 함수는 async / await / suspend 구문을 가지게 된다.
그리고 비동기 함수에서 블로킹 IO 함수를 호출하는지 계속 신경써야 한다는 것도 불편한 점 중 하나이다. 이런 경우에는 동일한 기능을 하는 비동기 버전의 함수를 사용하거나 그런 부분에 적절한 스케줄러를 할당해 논블로킹 부분과 분리해 주는 기법을 사용해야 한다.
결국 이 방식으로도 3번째 문제(전염성, 함수의 색 문제)가 해결되지 않았음을 나타내고, 마찬가지로 손실된 컨텍스트 문제인 2번째 문제도 해결되지 않는다. 일부 기술의 최근 버전에서는 손실된 스택 트레이스를 상당 부분 복구해 스레드 경계를 초월한 정보를 제공하기도 하는데 여전히 원래 스택과는 다르고 자연스럽지 않다.
Project Loom에서의 비동기 문제 해결
- 코드는 블로킹, 동작은 논블로킹
- 경량 스레드 - 파이버
- 컨티뉴에이션 + 스케줄러
Project Loom은 이를 해결하기 위해 다른 방식의 접근을 사용 하는데 OS 스레드(실) 아닌 파이버(섬유)라는 경량 스레드를 제공하고 이를 사용한 블로킹 코드가 내부적으로 논블로킹으로 동작하게 하는 방식을 사용한다.
파이버는 컨티뉴에이션과 스케줄러의 조합으로 구성되며 이를 간단히 풀어보면 뭐 대충 이런식이다.
- 컨티뉴에이션 : 난 지금 열심히 일을 하다가(CPU를 사용하다가) IO 작업을 만났어. 난 대기해야 하니 사용하던 스레드는 반납하고 여기까지 일한 상태로 어딘가 있을게. 나중에 나를 불러주면 여기서부터 다시 일할거야.
- 스케줄러 : IO 작업이 끝났으니 아까 일한 너는 이제 다시 일을 하자. 이 OS 스레드(캐리어 스레드)를 할당해 줄테니 지금부터 5번 코어에서 다시 일을 진행하도록 해.
위에서 언급한 Why Continuations are Coming to Java 에 나온 코드 일부분을 한번 보자.

위 코드를 보면 Fiber에서 동작하다 블로킹 구간에서 진입하는 경우 실제 스레드가 블로킹되는 것이 아니고 LockSupport의 park()가 호출되는 것을 알 수 있다.
(초기 형태이며 현재 버전에서는 Fiber 클래스 대신 VirtualThread 클래스로 변경되었다.)
Project Loom 초기에 Thread와 Fiber가 Strand(실가닥)의 자식 타입이 될 것인지 아니면 Thread 타입에 통합할 것인지에 대해 다양한 논의가 있었는데 현재 버전에서는 Thread에 통합(VirtualThread) 되었으며 이를 통하여 기존 코드를 거의 변경하지 않고 Fiber의 장점을 취할 수 있게 되었다.
이 추상화에 대해 RPC 추상화 문제와 동일한 실수를 반복할 수 있다는 반대 의견들도 있었으나 결국 Thread에 통합하는 걸로 결정 되었고 가장 Java 다운 결정이라고 생각된다.
또한 개인적으로 이 추상화가 RPC 문제만큼 심각한 문제를 야기할 것이라고 생각 되지도 않는다.
VirtualThread는 Thread와 동일한 방식으로 사용

RPC 추상화 문제란?
- RPC 원격 호출을 추상화하여 일반 함수 호출처럼 사용할 수 있도록 하였으나 로컬 함수와 원격 함수 호출이 근본적으로 다른 점에서 야기되는 문제들
- 원격 호출은 정확한 파라미터로 호출하였더라도 로컬 호출과 다르게 언제라도 실패할 수 있으며 응답 시간도 예측할 수 없다. 또한 원격 호출이 실패하였으나 원격지에서는 성공하였을 수도 있다.
최신 버전 Loom에서 변경된 park() 메소드 및 (Thread의 상태값과 다른) VirtualThread의 status 값은 아래 그림에서 참고할 수 있다.
- JDK16+Loom 에서의 park() 코드에서 VirtualThread 타입을 사용하는 모습
Project Loom에서의 park() 메소드
Continuation을 이용하는 doPark()
- VirtualThread의 상태
- NEW / STARTED / RUNNABLE / RUNNING / PAKING / PARKED / PINNED / YIELDING / TERMINATED
- Thread의 상태와는 다르다.
- NEW / RUNNABLE / BLOCKED /WAITING / TIMED_WAITING / TERMINATED
Virtual Thread Status



그런데 여기서 한가지 의문이 들 수 있다.
코틀린의 코루틴을 사용해 본 사람은 알겠지만 여기서 제공하는 suspend 함수 역시 동기 코드처럼 작성하고 비동기로 동작하며 컨티뉴에이션을 사용하는 것 까지도 파이버와 유사해 보인다.
그런데 왜 코루틴은 위에서 제기한 문제 중 첫번째 문제 외에 다른 문제들(빈약한 스택트레이스와 함수의 전염성 문제)을 해결하지 못하는가?
async / await, suspend function 과 Project Loom 의 차이
- 컴파일러의 마법
- vs 네이티브의 지원
왜냐하면 근본적으로 두 가지의 접근 방식이 다르다. 코틀린은 컴파일러가 마법을 부리는 것이고(javascript와 c#도 마찬가지), Loom에서는 JVM native가 이를 지원한다.
예를 들면 코루틴에서는 코틀린 컴파일러가 suspend가 붙은 메소드를 Continuation을 인자로 받는 메소드로 변경하며 내부도 각 중단점을 기준으로 각각의 분할된 코드를 담고 있는 switch 문으로 변경된다.
이는 SCOUTER에서 코루틴으로 개발된 코드의 프로파일링 정보에서도 확인할 수 있다.
 |
| suspend function을 사용하는 코드 예제 |
컴파일러가 위 메소드를 아래 코드로 변경한다.
String testWebCallWithCoroutine1(ServerHttpRequest);
# 컴파일러 -->
Object testWebCallWithCoroutine1(ServerHttpRequest, Continuation); |
| SCOUTER에서는 변경된 메소드로 보여진다 |
JVM에서 Project Loom을 위한 지원
- Socket의 블로킹 부분 -> 논블로킹으로 변경
- java.util.concurrent 논블로킹으로 변경
- Thread.sleep() 논블로킹으로 변경
- ThreadLocal, Thread.currentThread()에서 Virtual Thread 지원
Java의 블로킹 라이브러리가 어떻게 논블로킹 방식으로 변경 되었는지는 자바 소켓을 통해서 한번 확인해 보도록 하자.
재구현된 Legacy Socket
- JEP 353: Reimplement the Legacy Socket API
- Java 코드와 네이티브 코드가 섞여 개발된 기존 Socket의 구조 개선
- Project Loom을 지원하는 형식
- since Java 13 : PlainSocketImpl --> NioSocketImpl
그래서 이 변화에 별 이득이 없어 보이지만 Project Loom의 코드를 살펴보면 이러한 변경이 어떻게 활용되고 있는지 확인할 수 있으며 이러한 접근을 통해 기존 코드를 거의 변경하지 않고도 논블로킹의 이점을 그대로 누릴 수 있게 한다.
- PlainSocketImpl의 read() 메소드
- read() --> (native) socketRead0() : 블로킹
- NioSocketImpl의 read() 메소드
- read() --> timedRead() --> park --> Net.poll() : 논블로킹
- 클라이언트 코드 입장에서는 블로킹
- Java16+Loom의 NioSocketImpl에서 read() 메소드
- read() --> timedRead() --> park --> VirtualThreads.park() --> Continuation.yield()
- 클라이언트 코드 입장에서는 블로킹
- yield를 통해 OS 스레드 반환 (스레드 미점유)
 |
| PlainSocketImpl에서 사용되는 socketRead0 메소드 |
 |
| NioSocketImpl에서 timedRead() 메소드 |
 |
| NioSocketImpl의 park() 메소드 |
② NioScoketImpl에서는 Net.poll()의 논블로킹 API를 사용하지만 클라이언트 코드 입장에서는 while문이 종료되어야 응답을 받으므로 여전히 블로킹이다.
 |
| JDK16+Loom에서 변경된 park() 메소드 |
③ Project Loom에서는 park() 메소드가 VirtualThreads.park()를 이용하는 것으로 변경 되었으며 이 코드의 내부는 앞에서 보았듯이 Continuation.yield()를 수행하고, 결국 캐리어 스레드를 반납하고 스케줄러가 다시 불러주기를 기다리게 된다.
따라서 클라이언트 코드 입장에서는 기존 코드를 전혀 변경하지 않는 블로킹 코드이며 또한 Thread(=여기서는 VirtualThread)를 점유한 것처럼 보이지만 실제로는 OS 스레드를 점유하지 않게 되므로 앞서 얘기한 성능과 읽고 유지보수 하기 쉬운 코드라는 두 마리 토끼를 다 잡게 된다.
이는 소켓 대기 시의 스택 트레이스에서도 확인할 수 있으며 스택 트레이스에는 이 요청이 흘러온 과정이 코드와 일치하는 수준으로 왜곡없이 나타나게 된다.
 |
| Java8에서 소켓 읽기 대기 |
 |
| Java 14에서 소켓 읽기 대기 |
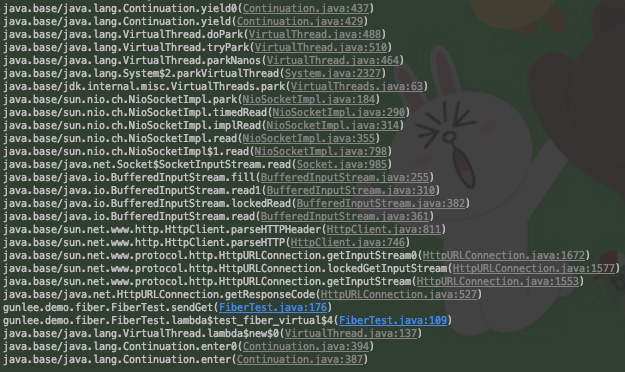 |
| Project Loom에서의 소켓 읽기 대기 |
Virtual Thread 의 간단한 사용법과 위 스택 트레이스를 생성하는 코드의 예제는 아래 gist에서 확인할 수 있다. (gunlee01/FiberTest.java)
Project Loom이..
- 해결하는 것
- 제어 흐름과 컨텍스트를 잃는 문제
- 전염성 / 함수의 색 문제
- 해결하지 못하는 것
- 자연스럽고 우아한 동시성 처리
Project Loom은 블로킹 형식의 코드가 논블로킹으로 동작함으로써 많은 비동기 프로그래밍이 가지고 있는 단점을 극복한다. 그리고 클라이언트 코드에서 스레드를 사용하는 방식을 유지해 기존 라이브러리를 그대로 사용해도 논블로킹의 이점을 얻을 수 있다
반면에 이전과 동일하게 낮은 수준의 동기화 요소를 직접 다루므로 앞에서 잠시 얘기했던 비동기 프로그램의 장점인 우아하고 자연스러운 동시성을 스스로 달성하지는 못한다.
예측해 보자면
웹플럭스에서 코틀린 코루틴을 사용하는 방식은 파이버보다 더 나은 장점이 거의 없으므로 파이버를 이용한 동기식 프로그래밍 형태로 전환될 것이다. 또한 비즈니스 로직을 다루는 일반적인 서버 API 개발에서는 webflux 같은 reactive streams를 이용한 방식 역시 지금보다 훨씬 덜 선호 될 것이다.
하지만 스트림의 효율적인 처리가 필요하거나 병행 처리 등을 위해 reactive streams나 future 같은 비동기 요소는 여전히 사용될 것이고 상호 대체하기 보다는 파이버가 비동기 프로그래밍을 좀 더 효율적으로 처리되도록 도와주는 방식으로 같이 사용 될 것이다.
(예를 들면 비동기 프레임워크에서 IO를 처리하기 위해 Callback, Listener, Future등을 사용해 복잡하게 처리했던 부분을 그냥 파이버 블로킹으로 처리한다던지...)
캐리어 스레드의 블로킹과 다른 문제들
- JNI로 호출된 네이티브에서 블로킹되는 경우 : 캐리어 스레드 블로킹!
- Reflection의 Method.invoke()는 현재 네이티브 메소드
- Loom에서는 MethodHandle을 이용하는 순수 자바로 변경됨
- syncronized, wait 구문 : 캐리어 스레드 블로킹!
- 수백만개 파이버를 스레드 덤프로 떨어뜨리기?
마지막으로 현재 버전의 Loom에 남아있는 몇 가지 문제를 집고 넘어가자.
기존 동기 코드가 내부적으로 비동기로 동작하도록 java.util.concurrent 및 그 외 많은 부분이 변경되어야 하는데 이 부분은 대부분 진행되었다. Thread.sleep() 이나 각종 블로킹 큐의 블로킹 동작들도 이미 캐리어 스레드 논블로킹으로 동작한다.
단 JNI를 통해 호출한 네이티브 메소드에서 블로킹 IO를 수행하는 부분이 있으면 캐리어 스레드가 블로킹되고 syncronized 구문에서도 캐리어 스레드가 블로킹 된다. 하지만 JNI 쪽은 일반적으로 거의 사용하지 않으므로 크게 문제될 것은 없으며 syncronized 내부에서 긴 IO 동작을 사용하고 있다면 이는 java.util.concurrent 패키지로 대체하는 것을 권장하고 있다.
대신 이런 코드가 수행되면 이를 탐지하여 경고해 주는 기능도 Project Loom에 탑재되어 있다.
다만 syncronized 에 대한 제약은 어느 시점에 해결될 것이라고 한다
그리고 동시에 수백만 개의 스레드를 다룰 수 있다는 것이 갖는 근본적인 제약이 있는데, 만약 수백만 개가 실제로 동작하고 있다면 스레드 덤프에서 수백만 개의 스레드 상태를 다 보여주는 것이 적절한 것인가? 라는 고민이다.
당연히 그렇게 보여주기는 어려울 것이며, 그래서 현재 버전의 스레드 덤프에는 파이버(Virtual Thread)가 포함되지 않고, 앞으로도 그럴 것으로 예상된다. 또한 Virtual Thread를 순회할 수 있는 API도 제공되지 않는다.
다만 이러한 것들은 다양한 도구들을 통해 다양한 방식으로 극복될 것이며, SCOUTER에서는 액티브 서비스를 파이버의 숫자로 보여주고, 오래 점유하고 있는 상위 수천 개 정도의 파이버 상세 정보를 추적하여 필요한 경우 해당 스레드들의 스택 트레이스를 보여주는 식으로 지원할 생각이다.
Project Loom은 언제 릴리즈 되는가?
- 나도 궁금
- 2022년 early에 나오면 참 좋겠다.
그러면 언제쯤 Loom이 정식 릴리즈로 JDK에 포함될 것인가?
이게 너무 궁금해서 여기 저기 찾아보았지만 아직 예측 일정 조차 어디에도 언급되지 않고 있었다.
아직 프리뷰 단계도 도달하지 못한 얼리 액세스 단계이고 Java의 느린 행보로 보건데 아마 빠르게 진행되어도 최소한 2022년은 되어야 기대라도 해 볼 수 있을 것 같다.
(Java 17에 프리뷰로 들어간다고 해도 두 번 정도 프리뷰 버전이 나올테니...)
그리고 프로젝트 룸은 클라이언트 코드 관점의 개발 뿐 아니라 스레드를 넘나드는 파이버에 대해 디버거나 프로파일러 관점에서의 지원도 필요한 부분이라 엄청나게 빠른 속도로 진행하기 어려운 부분도 있다.
하지만 이 프로젝트에 많은 사람들이 관심을 가지고 있고, 또한 프로젝트의 세가지 목표인 파이버, 컨티뉴에이션(퍼블릭 노출의), 꼬리 호출 3가지 주제 중에 파이버만 완성되는 단계에서 정식 릴리즈를 하겠다고 하였으니 2022년에 나오기를 희망해 봐야겠다.
참고
- https://cr.openjdk.java.net/~rpressler/loom/Loom-Proposal.html
- https://www.infoq.com/presentations/continuations-java/
- https://www.youtube.com/watch?v=fOEPEXTpbJA&list=WL
- https://mbien.dev/blog/entry/taking-a-look-at-virtual
- https://blog.softwaremill.com/will-project-loom-obliterate-java-futures-fb1a28508232
- https://openjdk.java.net/jeps/353
- http://journal.stuffwithstuff.com/2015/02/01/what-color-is-your-function/
- https://medium.com/@elizarov/how-do-you-color-your-functions-a6bb423d936d
- https://twitter.com/rafaelcodes/status/1176229314112741377



너무 잘 읽었습니다. 많이 배웠네요!
답글삭제정말 좋은 글 감사합니다
답글삭제스노우 인터뷰이로 갔었는데, 기억하실지 모르겠네요 ㅎㅎ
답글삭제글 재밌고 유익하게 잘 읽었습니다! loom 앞으로도 주시해야겠네요
감사합니다 잘 읽고 갑니다
답글삭제https://openjdk.java.net/jeps/8277131
답글삭제Virtual Thread가 JEP Draft 로 들어갔습니다.
오! 소식 감사합니다.
삭제개쩌네요 감사합니다
답글삭제좋은 글 감사함니다
답글삭제잘 읽었습니다. 좋은 포스팅 감사합니다.
답글삭제쓰신 글 이제서야 이해했습니다.
답글삭제감사합니다. 꾸벅 ~